Data-flo tutorial
A short introduction
Data-flo (https://data-flo.io/) is a system for customised integration and manipulation of diverse data via a simple drag and drop interface.
For Data-flo documentation, go to https://docs.data-flo.io/introduction/readme
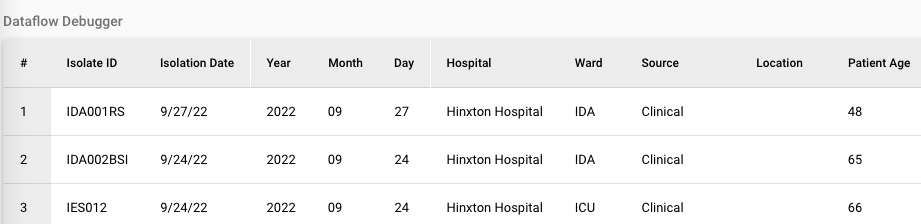
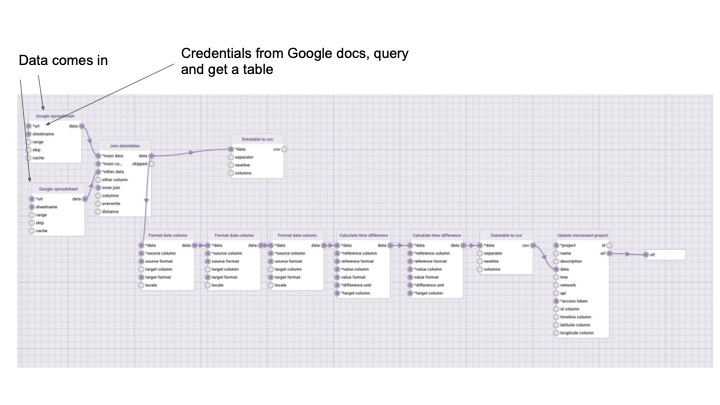
Data-flo can easily combine epidemiological data, genomic data, laboratory data, and various metadata from disparate sources (i.e., different data systems) and formats.
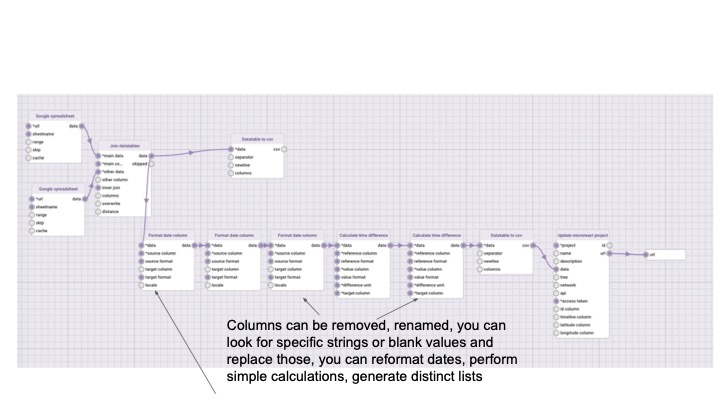
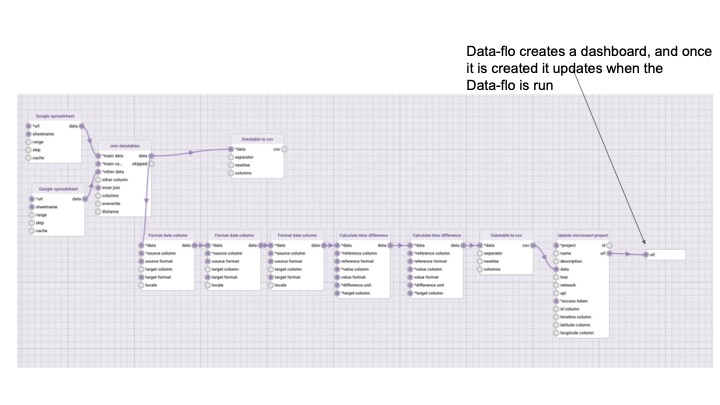
Data-flo provides a visual method to design a reusable pipeline to integrate, clean, and manipulate data in a multitude of ways, eliminating the need for continuous manual intervention (e.g., coding, formatting, spreadsheet formulas, manual copy-pasting).
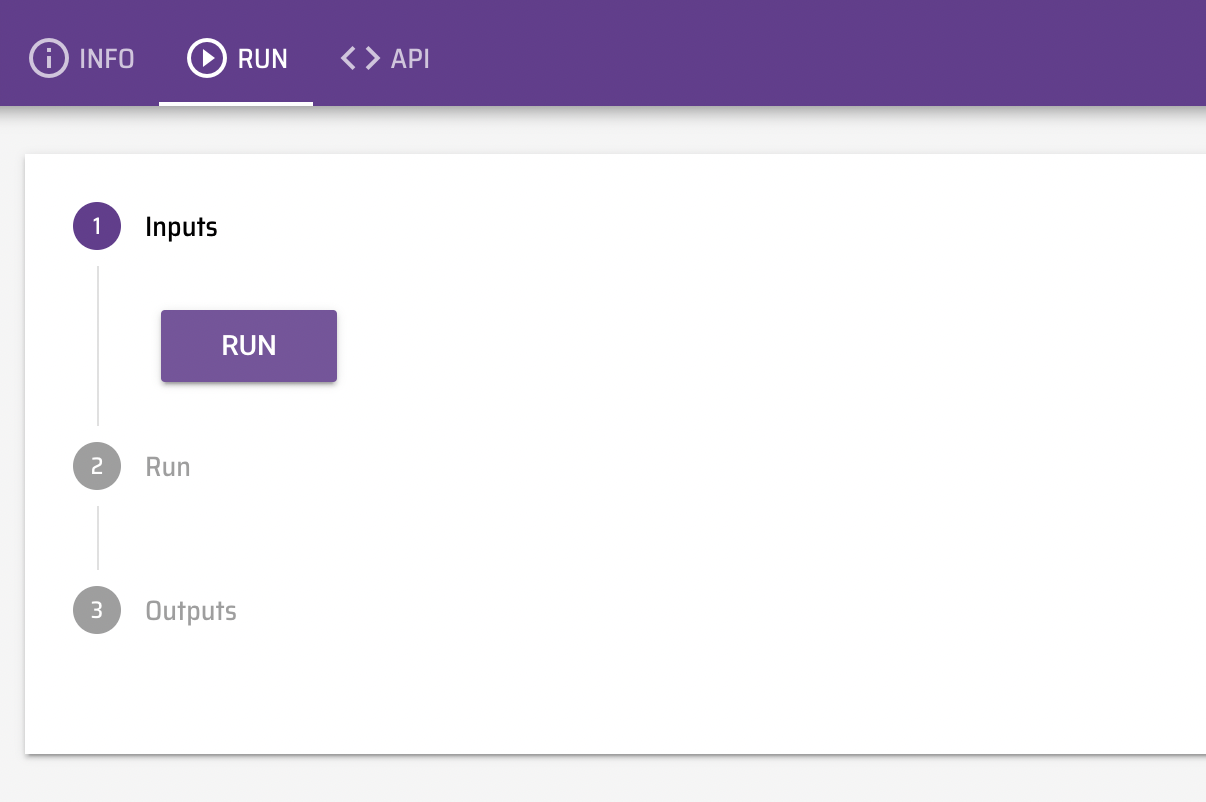
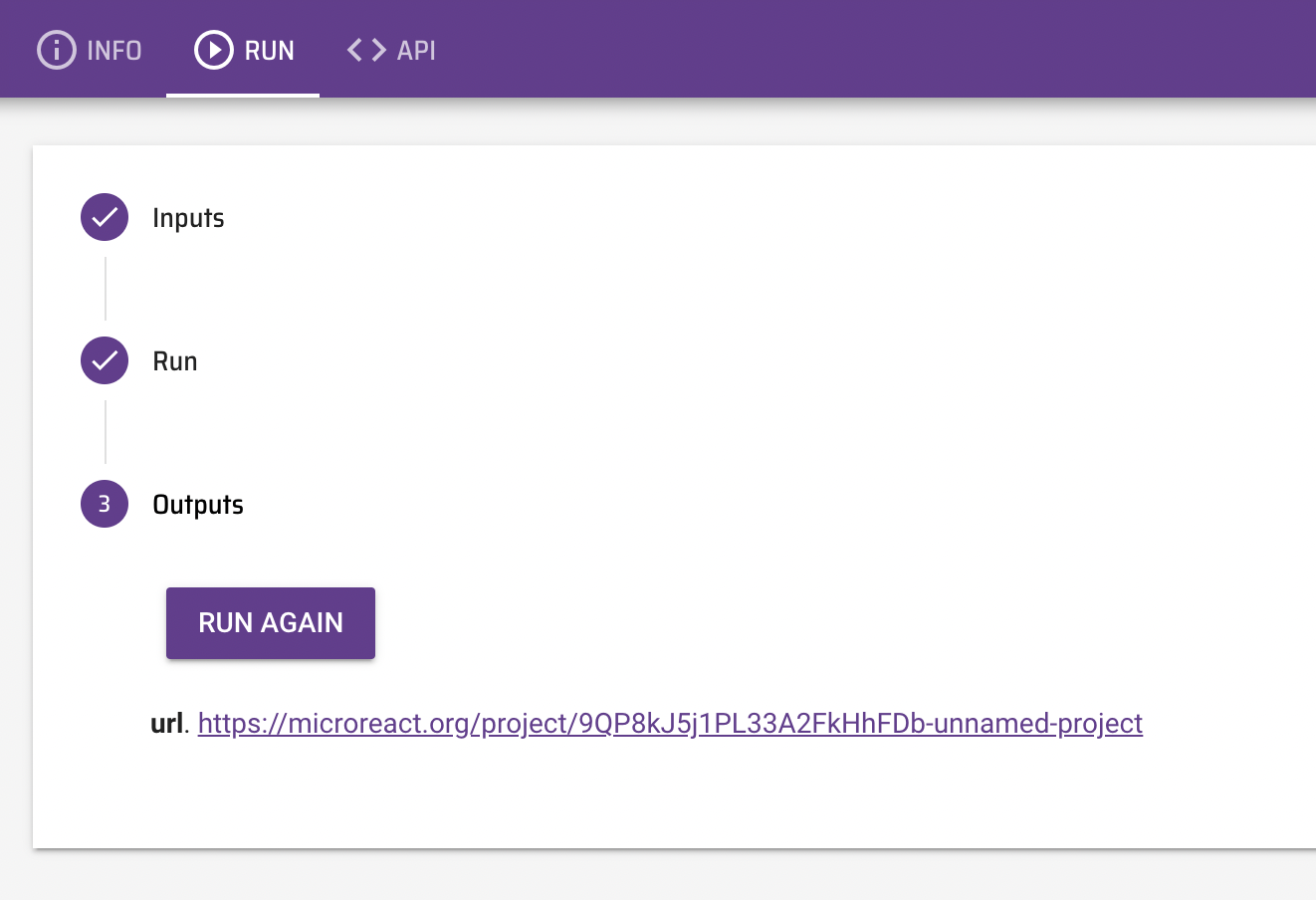
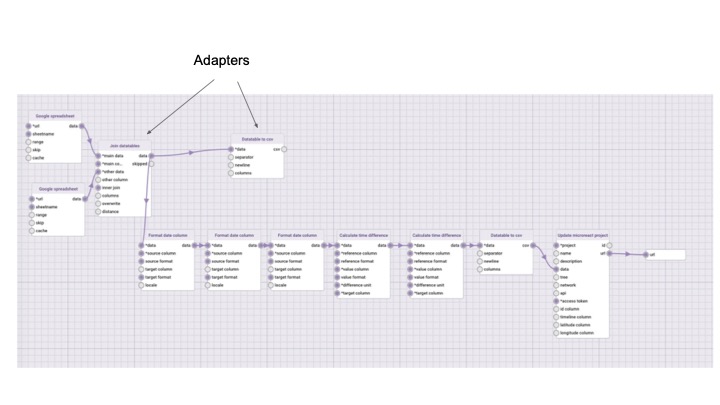
Data-flo pipelines are combinations of ready-to-use data adaptors that can be tailored, modularised and shared for reuse and reproducibility. Once a Data-flo pipeline has been created, it can be run anytime, by anyone with access, to enable push-button data extraction and transformation. This saves significant time by removing the bulk of the manual repetitive workflows that require multiple sequential or tedious steps, enabling practitioners to focus on analysis and interpretation.
Required internet browsers: Google Chrome or Mozilla Firefox
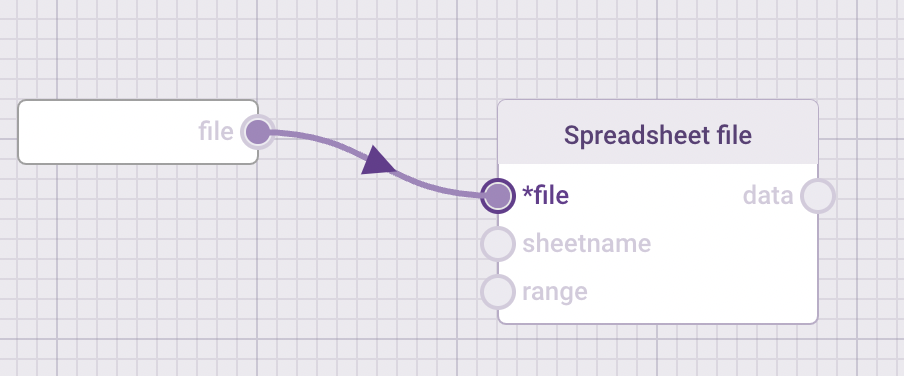
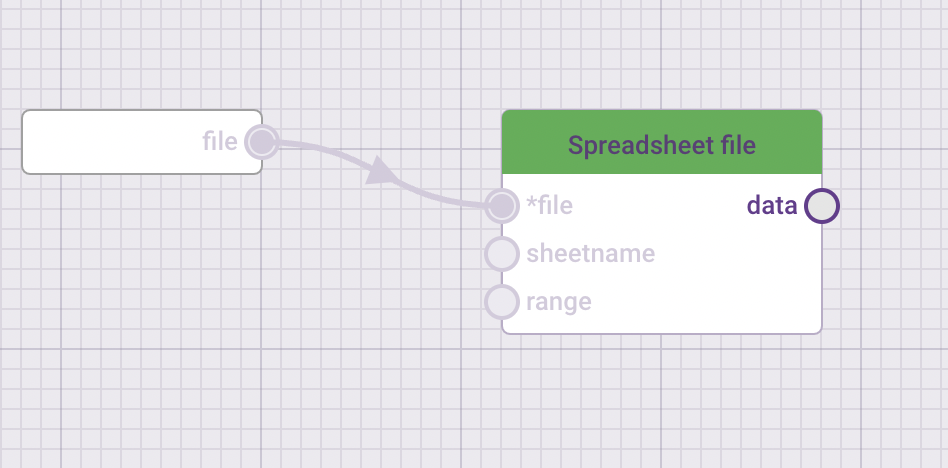
“Steps” in Data-flo are called ADAPTORS. There are three main types of adaptors, which serve different functions.
Importing data
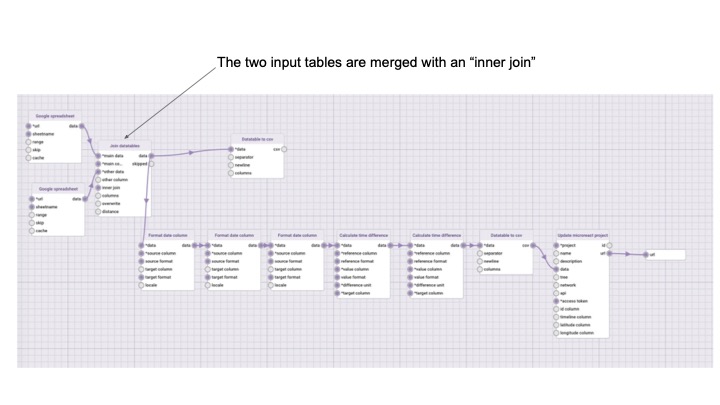
Manipulating & transforming data
Exporting data
![]()